Introduction
Mélodium is a language and runtime for building robust stream-processing, event-driven, and distributed software. Unlike conventional languages that process data step by step, Mélodium describes programs as graphs of treatments connected by data flows, where execution is driven by data availability rather than instruction order.
This book covers the purpose of Mélodium, its core concepts, and how to program and work with it. For the full API reference, see the Mélodium Standard Reference. Source code is available on the repository. The Official Project Website has news and release information.
Mélodium and this book are a work in progress, aiming to evolve and grow significantly with time. The information presented here may not always be up to date with the current state of the project. All this work is done with passion and any feedback is welcome.
Purpose
Mélodium is designed for programs that process continuous, unbounded data flows: event-driven servers, signal pipelines, distributed workers, and anything that must keep running even when parts of the system encounter problems.
Most languages treat data as discrete values moved through memory step by step, which works well for many tasks. The difficulty appears when data never stops arriving, does not fit in memory, or must be processed across many machines simultaneously. Managing threads, queues, backpressure, and error handling in those situations requires significant effort and leaves many failure modes up to the developer.
Mélodium takes a different approach. A program is described as a graph of treatments connected by data flows. Execution is driven by data availability, not instruction order. The graph is fully validated before any execution starts, catching type mismatches and structural errors at startup. Parallelism and scalability emerge naturally from the graph structure, without explicit threading code.
Installation
Mélodium can be installed through different ways. There are prebuilt binaries ready to use for major platforms, as well as installers.
Installers and binaries
For major platforms, such as Linux, Mac, and Windows, Mélodium is released as package or installer, depending on the common practice related to the operating system. Standalone binaries stored in archive files are also available for all these platforms.
Please refer to the Download Page to get installer and prebuilt binaries.
Compilation
Mélodium can be build and installed through the Rust cargo command.
This method is available for all supported platforms, and require to have the Rust Environment installed and ready to work.
Please refer to the Rust Project to install the Rust compiler.
To build and install Mélodium:
cargo install melodium
Please note this may take a while, depending on the network connection and machine proceeding to compilation.
Refer to the Supported Platforms chapter to check the Mélodium compatibility.
Software
In this chapter is explained the Mélodium software itself.
Its usage, the command-line interface, the possible project formats, and the supported platforms are all detailed in their own subchapters.
General Use
Mélodium, as software, can be essentially resumed as a single executable binary.
The Mélodium binary doesn’t require to be at any specific location on the system, and doesn’t require more permissions nor privileges than a usual executable program. This said, it have to be in the PATH of the user in order to work correctly with standalone Mélodium script and program files.
If Mélodium has been installed through a system-dedicated installation method these requirements are met, such as with an installer on Windows or package on Linux.
Mélodium software is very similar to what can be found with other programming technologies, such as Python or Java, among others. The Mélodium executable binary is the implementation of the Mélodium programming language, and receive Mélodium script and program files to execute them.
Direct Call
Mélodium can be called directly through command line, using the melodium command, followed by the name of the script or program file that has to be executed.
By default, the main entrypoint will be used, and possible following parameters will be given to the designated treatment.
A Mélodium program can declare any number of entrypoints, and having a main one is optionnal. In general, a program with a main entrypoint is aimed to be used directly, while projects without main entrypoint (either none or multiple others) are libraries.
Calling a Mélodium program is as simple as:
melodium my_program.mel
And it is strictly equivalent to:
melodium my_program.mel main
If arguments needs to be passed to the program, they can be specified as any CLI arguments:
melodium my_program.mel [ENTRYPOINT] --my_number 42 --my_boolean true
To see what entrypoints a Mélodium program proposes, use the info command:
melodium info my_program.mel
For more CLI usage details, please refer to the Command Line Interface section.
Executable Scripts and Programs
Mélodium scripts files (with .mel extension) and packaged files (with .jeu extension) can be called directly as-is if they have been designed for this use by the authors.
On POSIX systems, it require for the file to be marked as executable (
xpermission), and in case of.melfile, to start with the#!/usr/bin/env melodiumshebang line.
This means Mélodium scripts and programs can be called as simply as any shell or general executable file:
my_program.mel --my_number 42 --my_boolean true
Command Line Interface
Mélodium is distributed as a program that have extensive and growing CLI, to see the exhaustive commands and options list:
melodium help
Run program
Launch a Mélodium program:
melodium <FILE>
or
melodium run <FILE>
or launch a specific command in Mélodium program:
melodium run <FILE> <CMD> [ARGS…]
To see specifics of a program entrypoints:
melodium run <FILE> <CMD> --help
Note: If Mélodium is installed on system, standalone
.melfiles and.jeufiles are directly callable as-is through command line.
Program information
See the commands and options of a program:
melodium info <FILE>
Check code
Check a Mélodium program validity:
melodium check <FILE>
Generates documentation
Generates documentation, as mdBook, for a Mélodium package:
melodium doc --file <FILE> <OUTPUT>
Build Jeu files
To build a Jeu file from a project:
melodium jeu build <PROJECT> <OUTPUT_FILE>
Formats
Mélodium projects can come in three formats:
- a project tree with structure of
*.melscript files; - a standalone
*.melscript file; - a packaged project as
*.jeufile.
These three formats have slightly different purposes and are detailed in their own subsection.
Project Tree
This project format consists of a tree of *.mel script files dispatched in directories, where each file and directory are their own area.
my_project/
├── baz.mel
├── Compo.toml
├── foo
│ └── bar.mel
├── foo.mel
└── main.mel
At the root of the project is a Compo.toml file, containing the information related to the project itself, such as its name, dependencies, entrypoints, and so on.
This project format is the most useful for development, as it is easily manageable with any code editor and fits with versioning systems like Git.
Standalone File
This format is, as its name suggest, a single *.mel script file.
Everything is contained in a single Mélodium script, including the information about dependencies.
A standalone project file is basically a usual *.mel file with special heading inside.
#!/usr/bin/env melodium
#! name = my_project_name
#! version = 0.1.0
#! require = std:0.8.*
/*
Just a usual Mélodium script afterwards.
…
*/
The details about standalone files are given in the Standalone Files chapter.
This project format is useful for quick scripts edition and deployment, prototyping, and to use as system tool.
Packaged Project
Mélodium have a project package format called Jeu. It is basically a compressed archive format with some prefixed data for Mélodium and host system handling.
When shipping a project, either for testing, deployment, or any use case better handling one-file program, the Jeu format is indicated.
To package a project as Jeu file, use the jeu subcommand:
melodium jeu build <PROJECT> <OUTPUT_FILE>
Jeu files have .jeu extension, and are directly usable as programs on systems where Mélodium is installed.
As Jeu files are already highly compressed files (using the LZMA2 algorithm), it is in general not useful to re-compress it inside other archive formats.
Supported Platforms
Mélodium supports multiple platforms. The term “Platform” refers to a set of operating system, machine architecture, and compilation method; also known as “target” by Rust developers.
Directly supported platforms are platforms for which Mélodium binaries are released.
| Platform | Notes |
|---|---|
aarch64-apple-darwin | ARM64 macOS (11.0+, Big Sur+) |
aarch64-pc-windows-msvc | ARM64 Windows MSVC |
aarch64-unknown-linux-gnu | ARM64 Linux (kernel 4.1, glibc 2.17+) |
aarch64-unknown-linux-musl | ARM64 Linux with MUSL |
i686-pc-windows-gnu | 32-bit MinGW (Windows 7+) |
i686-pc-windows-msvc | 32-bit MSVC (Windows 7+) |
i686-unknown-linux-gnu | 32-bit Linux (kernel 3.2+, glibc 2.17+) |
i686-unknown-linux-musl | 32-bit Linux with MUSL |
x86_64-apple-darwin | 64-bit macOS (10.12+, Sierra+) |
x86_64-pc-windows-gnu | 64-bit MinGW (Windows 7+) |
x86_64-pc-windows-msvc | 64-bit MSVC (Windows 7+) |
x86_64-unknown-linux-gnu | 64-bit Linux (kernel 3.2+, glibc 2.17+) |
x86_64-unknown-linux-musl | 64-bit Linux with MUSL |
Other platforms support
Mélodium may work on platforms that are not listed as Directly supported platforms.
For those platforms, it is needed to build and install Mélodium through the Rust cargo command.
cargo install melodium
These platforms are notably Linux/BSD-like ones, as well as less common machine architecture for operating systems already supported.
For a full list of possible target, please refer:
- to the Mélodium project repository CI checks file;
- to the Rust platform support list, where any
std-compatible target should hypothetically work.
If you have specific needs for a given platform (either getting prebuild binaries or making the compilation possible), please open a ticket on the project repository.
Specificities
Some platforms may have specificities. The aim is not to be exhaustive but to explain the reasons of these differences.
Linux GNU vs. MUSL
Without deeping dive into the details, *-gnu for Linux platforms means Mélodium rely on glibc implementation embedded by the host distribution, and *-musl means Mélodium executable is statically linked with the musl libc and so is fully autonomous in and by itself.
While both are good choice, *-gnu may not fit in some situations, such as distributions that don’t ship with glibc (most notably Alpine Linux), when *-musl should work anywhere, at the cost of some extra kilobytes embedded within the executable itself.
From user perspective, no difference should be noticed in any case.
Windows GNU vs. MSVC
On Windows, *-gnu means Mélodium is built using the GNU MinGW toolchain, while *-msvc means it is built using the Microsoft Visual Studio toolchain.
Both versions are totally equivalent in terms of usage and compatibility on Windows platforms from a user and developer point of view. Difference is mainly important for low-level software developers who might want to use one over the other in some very specific situations.
Again, from user perspective, no difference should be noticed in any case. If nothing explicitly restrain the choice between both, any of them can be picked indifferently.
Programming
This chapter covers the Mélodium programming model in full, from core concepts to project organization.
It is organized as follows:
- Concepts: the mental model behind Mélodium: how data flows, what models and treatments are, how connections and tracks work.
- Elements: the syntax and semantics of each language element: treatments, models, contexts, functions, and data types.
- Core types, Parameters, Generics, Traits: the type system in detail.
- Project Organization: how to structure, configure, and package a Mélodium project.
- Runtime: how Mélodium validates and executes a program.
First Program
This page walks through the smallest complete Mélodium program, introducing the key syntax before the full concept chapters.
The program
The program starts up, emits a greeting string, and logs it:
use std/engine/util::startup
use std/flow::emit
use std/engine/log::logInfos
treatment main()
{
startup()
greet: emit<string>(value="Hello from Mélodium!")
logInfos(label="hello")
startup.trigger -> greet.trigger,emit -> logInfos.data
}
Reference for startup, emit, logInfos
What each part does
use declarations import treatments from packages. The three imports here come from the std package: startup triggers at program launch, emit produces a value on demand, and logInfos prints a stream of strings to the engine log.
treatment main() is the entry point. It has no inputs or outputs because it is the root of the program: data originates here rather than flowing in from outside.
The treatment body declares three inner treatment instances and connects them:
startup()fires aBlock<void>trigger when the program is ready to run.greet: emit<string>(value="Hello from Mélodium!")is an instance ofemit, labeledgreet, configured to emit that specific string when triggered.logInfos(label="hello")receives aStream<string>and prints each value to the log under the labelhello.
The connection line wires them together:
startup.trigger -> greet.trigger,emit -> logInfos.data
Read this left to right: startup.trigger feeds into greet.trigger, which starts the emit; greet.emit feeds into logInfos.data, which prints the string. The , shorthand chains the output of one treatment directly to the input of the next.
Self is not needed here because main has no declared inputs or outputs of its own. In treatments that do, Self.input_name and Self.output_name refer to those ports.
Project layout
To run this as a project, create the following structure:
hello/
├── Compo.toml
└── main.mel
Compo.toml:
name = "hello"
version = "0.1.0"
[dependencies]
std = "0.10.1"
[entrypoints]
main = "hello/main::main"
main.mel contains the treatment shown above.
Running it
melodium run Compo.toml
Or as a standalone file without a project, add the metadata header to main.mel:
#!/usr/bin/env melodium
#! name = hello
#! version = 0.1.0
#! require = std:0.10.*
use std/engine/util::startup
use std/flow::emit
use std/engine/log::logInfos
treatment main()
{
startup()
greet: emit<string>(value="Hello from Mélodium!")
logInfos(label="hello")
startup.trigger -> greet.trigger,emit -> logInfos.data
}
Then run directly:
melodium main.mel
The engine log will output the greeting under the hello label. From here, the Concepts chapter explains the mental model behind treatments, connections, and tracks in full.
Concepts
Mélodium is a programming language oriented to various data, signal and trigger treatment, process orchestration, and infrastructure management. To do so, it relies on some concepts that are explained in this chapter.
General Orchestration
Mélodium is a language fully oriented to what happens with data. As such, in Mélodium, data and signals follows an ensemble of paths that brings it to different kind of treatments and processes.
Unlike many programming languages, Mélodium makes a total abstraction of the instruction order and don’t rely on a line-by-line execution scheme. Every element can run and be shared among different threads depending on the load, data availability, or orchestration optimization decision.
To proceed with those ideas, two major elements exists in Mélodium: models and treatments. Both are essential and can summarize the whole power of Mélodium, and are briefly explained here, more extensive explanations are made in their dedicated Elements chapters.
Models
Models are long-lived elements that persist for the entire execution of a program. They are the sources from which events occur and data arrives. A filesystem watcher, an HTTP server, or a SQL connection pool are all models. Models can be declared over other models, inheriting their capabilities.
Full syntax and examples are covered in the Models chapter.
Treatments
Treatments describe flows of operations applied to data. They can be seen as maps, where paths connect sources to destinations through different processing steps. All treatments within a treatment body can run simultaneously; declaration order has no meaning.
Full syntax and examples are covered in the Treatments chapter.
Connections
Connections are a specific element, they are the ways by which the events and data are shared among treatments, and ultimately creates the functionnal logic of a program.
Connections are made the most basic element by Mélodium logic, at the core of each treatment nature. Rules are quite soft about them, and the few basic restrictions that applies are:
- a connection cannot link different kinds of data input/output;
- a connection cannot create a cycle (the graph-oriented equivalent of an infinite loop with no termination);
- multiple connections cannot connect to the same treatment input.
These rules exist for determinism and safety: type matching is enforced at build time rather than at runtime; cycles would cause a treatment to feed its own input indefinitely with no way to stop; and requiring a single source per input ensures that the order of data arriving at a treatment is always predictable.
Inputs
Inputs are the way treatments receive data. There can be any number of input declared for a given treatment, the only constraint being that when using this treatment, all inputs it have must be connected to some output once.
Most of the treatments wait to receive some data before starting to process anything.
Outputs
Outputs are the way treatments send data. As for inputs, there can be any number of output declared for a given treatment, however any output can be connected to as many inputs as needed, or not be used at all.
Most of the treatments process data as long as their main functionnal outputs stay used, and stops when no more following treatments consume it.
Streaming
Inputs and outputs can be divided in two main categories, the streaming ones and the blocking ones. The streaming inputs and outputs are basically receiving and sending data as flow. There can be any amount of data corresponding to the associated type passed through streaming inputs and outputs. Streaming inputs and outputs are the general case of data transmission.
Blocking
The blocking inputs and outputs emit and take at most one and only one element of the given data type. This type of connection is specific for event transmission. It is generally used as trigger to start some processing.
The name “blocking” refers to the idea of a single block of data, not to suspending execution. A Block<T> port carries exactly one value, delivered as a whole unit, as opposed to a Stream<T> port which carries a continuous sequence of values.
Tracks
Tracks are the most implicit thing in Mélodium. When models are instantiated and treatments connected together, it creates a potential track. The track is the whole ensemble of treatments and flows between them, that are created together, live together, and disappear together.
A track always takes its origin from a model, which requests its initialization when needed and as many times as needed: for each file found, each incoming connection, or whatever the model’s purpose proposes. Each track follows the same defined chain of treatments, but runs independently. This is one of the core elements providing Mélodium its strong scalability.
For example, an HTTP server model creates one new track for every incoming request. Each track processes its request independently and concurrently, without any shared state with the others:
use http/server::HttpServer
use http/server::connection
use http/method::|get as |methodGet
// Each incoming GET /ping request spawns its own independent track.
treatment myApp[http_server: HttpServer]() {
connection[http_server=http_server](method=|methodGet(), route="/ping")
respond()
connection.data -> respond.data,result -> connection.data
}
All tracks share the same model (the HttpServer instance) as their source, but their data flows are entirely separate.
Runtime
Mélodium uses a runtime engine. Script files are fully parsed and their logic built and checked before any execution starts. This means type errors, missing connections, unsatisfied inputs, and dependency problems are all caught at startup, not mid-run.
When launching a Mélodium program, the following stages happen in order:
- Script textual parsing and semantic build - the source files are parsed and their syntax validated. Element declarations are collected and checked for structural correctness.
- Usage and dependencies resolution - all
useimports are resolved and external packages are loaded. Missing or incompatible dependencies are reported here. - Logic building - the full treatment graph is assembled and validated: connection types are checked, cycles are detected, and every input is verified to be satisfied. No code runs until this passes.
- Models instantiation - model instances are created and configured with their parameters. Startup behaviors (such as opening connections) occur here.
- Execution and tracks triggering - the program begins running. Models start producing events and spawning tracks.
Elements
This chapter explains the usage and implementation of Mélodium elements, that are:
- treatments,
- models,
- contexts,
- functions,
- data types.
Treatments
Treatments are the main element of the language, they can take parameters. Unlike functions, which list instructions to execute and apply changes on variables, treatments describes flows of operations that applies on data. It can be seen as a map, on which paths connects from sources to destinations, browsing through different locations with different purposes. Order of declaration has no importance, treatments will run when there are data ready to be processed, and all treatments can be considered as running simultaneously.
Within treatments are other treatments, that also take parameters, inputs, and provide outputs to the hosting treatment. Treatments are declared once, and then can be connected as many times as needed.
treatment myTreatment(var foo: u64, var bar: f64)
{
treatmentA(alpha=foo)
treatmentB(beta=bar, gamma=0.01)
treatmentA.output --> treatmentB.input
}

Connections
Connections are basically paths data will follow. Connection can connect treatments outputs to inputs, but also refers to the inputs and outputs of the hosting treatment itself. A connection always links an output and an input of the same type.
Self refers to the hosting treatment’s own ports. It is used in connections to wire the treatment’s declared inputs and outputs into its internal graph.
use fs/local::writeLocal
use std/text/convert/string::toUtf8
treatment writeText(filename: string)
input text: Stream<string>
output written_bytes: Stream<u128>
{
writeLocal(path=filename)
toUtf8()
Self.text -> toUtf8.text,encoded -> writeLocal.data,amount -> Self.written_bytes
}
Reference for writeLocal, toUtf8
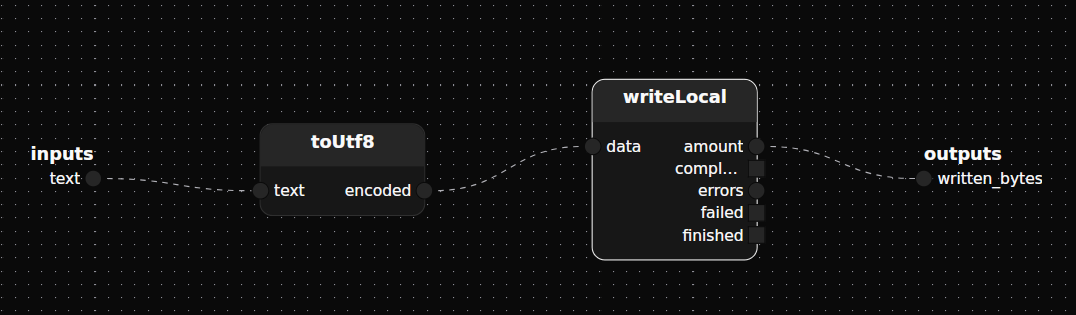
Multiple connections from the same element are totally legal, however overloading a treatment input or a host treatment output (Self) is forbidden.
Also, while omitting usage of a treatment output is legal, every input must be satisfied.
Finally, all host treatment outputs must be satisfied.
Inputs and outputs (and so connections) are either streaming or blocking. A streaming connection Stream<…> is expected to send continuously values from the specified type.
A blocking connection Block<…> is expected to send all-at-once.
This distinction mainly rely on the core treatments that are used and the intrinsic logic applied on data.
What developer should keep in mind is that streaming is the default unless blocking is required.
A specific kind of connection using the data type void exists. It is useful for transmitting information that something happens or should be triggered, schedule events, Block<void>; or to indicate continuation of something that doesn’t convey data by itself, Stream<void>.
Models
Models are elements that live through the whole execution of a program. They are declared by extending an existing library model and configuring its parameters.
A simple example using an HTTP server model:
use http/server::HttpServer
model MyServer() : HttpServer {
bind = "0.0.0.0"
port = 8080
}
Reference for HttpServer
The MyServer model extends HttpServer from the http package, fixing the bind address and port. It will live for the entire program execution, accepting connections as long as the program runs.
Models can also expose parameters that callers can override. Here is a database connection pool with a configurable maximum:
use sql::SqlPool
model MyDatabase(const max: u32 = 5) : SqlPool
{
min_connections = 1
max_connections = max
url = "postgresql://my-user@my-server:4321/my_database"
}
Reference for SqlPool
Models are instantiated by treatments in their prelude.
use sql::fetch
use sql::SqlPool
use std/data/map/block::entry
use std/data/map/block::get
use std/data/map::Map
use std/flow::trigger
treatment myApp()
/*
When model is instantiated, it is made available within the
treatment as if it where given as configuration parameter.
*/
model database: MyDatabase(max=3)
input user_id: Block<string>
output user_name: Block<Option<string>>
output user_level: Block<Option<u32>>
output user_failure: Stream<string>
{
userData[database=database]()
Self.user_id -> userData.user_id,user_name -> Self.user_name
userData.user_level --------> Self.user_level
userData.errors ------------> Self.user_failure
}
/*
Model can be given as configuration parameter.
*/
treatment userData[database: SqlPool]()
input user_id: Block<string>
output user_name: Block<Option<string>>
output user_level: Block<Option<u32>>
output errors: Stream<string>
{
/*
And then passed again as configuration parameter.
*/
fetchUser: fetch[sql_pool=database](
sql = "SELECT name, level IN users WHERE id = ? LIMIT 1",
bindings = ["user_id"]
)
entry<string>(key="user_id")
trigger<Map>()
Self.user_id -> entry.value,map -> fetchUser.bind,data -> trigger.stream
getUserName: get<string>(key="name")
getUserLevel: get<u32>(key="level")
trigger.first --> getUserName.map,value -> Self.user_name
trigger.first -> getUserLevel.map,value -> Self.user_level
fetchUser.errors -> Self.errors
}
Reference for fetch, entry, get, trigger
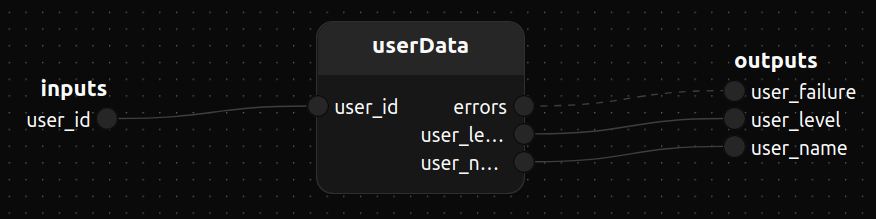
myApp

userData
In most cases, models are instantiated internally by treatments and not exposed, user developer can make direct call on model-dependent treatments without instantiating its own, just giving required parameters to the sequence. The cases where user may give its own defined model is to configure elements such as external software connections or interfaces.
Contexts
Contexts are data available through a whole track. Unlike parameters, they inherently exists and are accessible by all treatments requiring them, as long as the source of the track they are in provide it.
The calling treatments don’t have to explicitly pass any context to their inner called treatments.
Contexts have special naming convention, starting with @.
Context providing and requirement
Sources provide contexts, and treatments connected after that source can require the context to access it.
Requiring a context means the treatment can only be used in a track coming from a source providing such context.
The following minimal example shows the pattern: a source treatment provides @ConnectionId, and a downstream treatment requires it without being explicitly passed anything:
// A context carrying a connection identifier for the current track.
// In practice, contexts like this are provided by library models (HTTP, files, etc.).
treatment logRequest()
require @ConnectionId
input data: Stream<byte>
output result: Stream<byte>
{
// @ConnectionId[id] accesses the "id" field of the context.
// Its value comes from the track source, not from a parameter.
process(connection_id = @ConnectionId[id])
Self.data -> process.data,result -> Self.result
}
logRequest can only be used inside a track whose source provides @ConnectionId. Treatments further down the chain do not need to pass it explicitly: it is available to any treatment in the track that declares require @ConnectionId.
Below is a real-world example using the HTTP server, where @HttpRequest is provided by the connection source treatment:
use http/server::HttpServer
use http/server::connection
use http/method::|get as |methodGet
use http/server::@HttpRequest
use http/status::|ok
use http/status::HttpStatus
use std/data/string_map::|get
use std/data/string_map::|map
use std/data/string_map::StringMap
use std/flow::trigger
use std/flow::emit
treatment myApp[http_server: HttpServer]() {
connection[http_server=http_server](method=|methodGet(), route="/user/:user")
actionGetUser()
connection.data -> actionGetUser.data,result -> connection.data
trigger<byte>()
emitHeaders: emit<StringMap>(value=|map([]))
emitStatus: emit<HttpStatus>(value=|ok())
actionGetUser.result -> trigger.stream,start -> emitHeaders.trigger,emit -> connection.headers
trigger.start --------> emitStatus.trigger,emit --> connection.status
}
treatment actionGetUser()
require @HttpRequest
input data: Stream<byte>
output result: Stream<byte>
{
getUser(user_id = |get(@HttpRequest[parameters], "user"))
Self.data -> getUser.data,result -> Self.result
}
treatment getUser(user_id: Option<string>)
input data : Stream<byte>
output result: Stream<byte>
{
// Do some stuff…
}
Reference for HttpServer, connection, |get (http method), @HttpRequest,|get (map access)
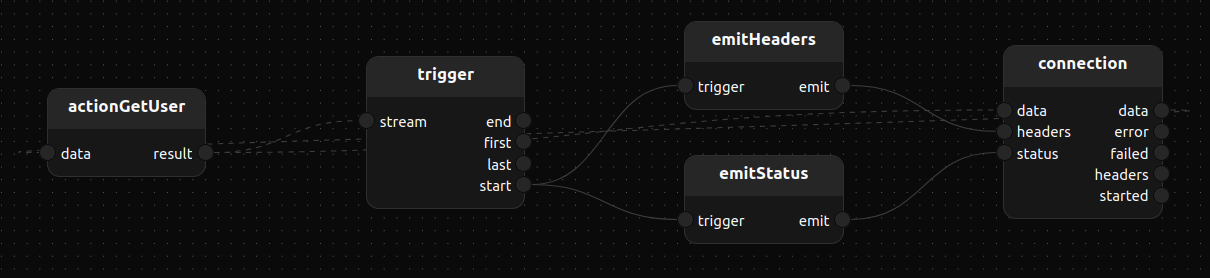
myApp
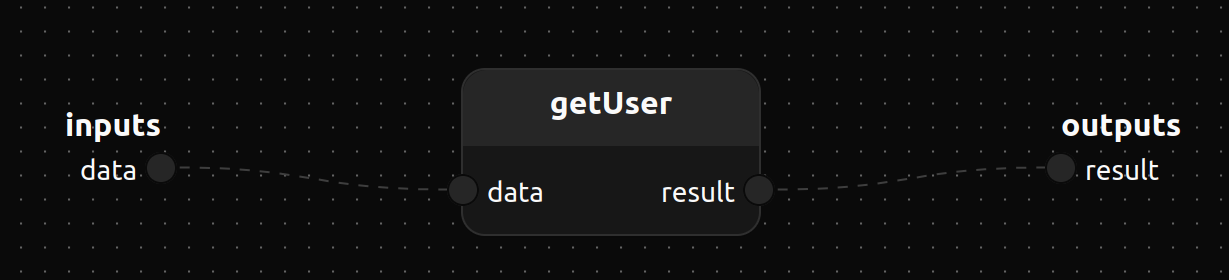
actionGetUser
As contexts comes at track creation, they are inherently variable data.
Functions
Functions are directly callable elements, as in any other programming language, they take parameters and return a value.
Functions in Mélodium are always pure, meaning they don’t have any side effects.
Functions are executed at program initialization or track creation, depending on whether their return value is used as a constant or variable parameter.
Functions are recognizable by the | symbol starting their name.
When used as a const parameter, the function is called once at startup and its result is shared across all tracks:
use http/status::|ok
use http/status::HttpStatus
// |ok() is evaluated once at program initialization.
model MyServer(): HttpServer {
default_status = |ok()
}
When used as a var parameter, the function is called once per track creation, so each track may receive a different value:
use std/data/string_map::|map
treatment myHandler()
// |map([]) is evaluated fresh for each new track.
var headers: StringMap = |map([])
{
// …
}
Data types
Data types are very basically the definition of data that can be given as parameter, transmitted through inputs and outputs, and more generally used across functions.
Mélodium packages can define their own data types, completing the core types, and they can be use-d in any place data type can be given.
One of the most common data type are the standard Map and StringMap types.
Data types can implements traits and be used as generics in some places.
Core types
Mélodium have multiple core data types, shared across four main categories:
- unsigned integers,
- signed integers,
- floating-point numbers,
- textual data,
on which bool, byte and void can be added.
All those types are described across their respective section, each type meets a specific purpose.
| Unsigned integers | Signed integers | Floating-point numbers | Text | Logic |
|---|---|---|---|---|
u8 | i8 | f32 | char | byte |
u16 | i16 | f64 | string | bool |
u32 | i32 | void | ||
u64 | i64 | |||
u128 | i128 |
Byte
| Type | Values | Size |
|---|---|---|
byte | Any 8-bits data | 8 bits / 1 byte |
A byte is basically the most atomic unit of data manipulable through Mélodium.
It represents any 8-bits data, without more assumption on what it could be.
Bool
| Type | Values | Size |
|---|---|---|
bool | true or false | 8 bits / 1 byte |
A bool is a boolean value that can be either set to true or false.
Conversion treatments are available for bools to be turned into bytes, numbers, or any kind of value.
Void
| Type | Values | Size |
|---|---|---|
void | None | 0 bit / 0 byte |
void does not hold any value. It just signals that something is happening or has happened. It is used in connections to transmit triggers or continuation indicators.
Block<void> carries a single trigger: it fires once to signal that an event occurred, such as initialization completing or a condition being met. Stream<void> carries a continuous series of signals, for example to indicate that items are being processed without conveying the items themselves.
use std/flow::trigger
use std/flow::emit
// trigger produces a Stream<void> that fires once per item passing through.
// emit<void> can fire a Block<void> to signal that setup is done.
trigger<string>()
emitDone: emit<void>(value=_)
Unsigned integers
| Type | Range | Size |
|---|---|---|
u8 | 0 to 2⁸-1 (255) | 8 bits / 1 byte |
u16 | 0 to 2¹⁶-1 (65,535) | 16 bits / 2 bytes |
u32 | 0 to 2³²-1 (4,294,967,295) | 32 bits / 4 bytes |
u64 | 0 to 2⁶⁴-1 ( > 18×10¹⁸) | 64 bits / 8 bytes |
u128 | 0 to 2¹²⁸-1 ( > 34×10³⁷) | 128 bits / 16 bytes |
Signed integers
| Type | Range | Size |
|---|---|---|
i8 | -2⁷ (-128) to 2⁷-1 (127) | 8 bits / 1 byte |
i16 | -2¹⁵ (-32,768) to 2¹⁵-1 (32,767) | 16 bits / 2 bytes |
i32 | -2³¹ (-2,147,483,648) to 2³¹-1 (2,147,483,647) | 32 bits / 4 bytes |
i64 | -2⁶³ ( ≈ -9×10¹⁵) to 2⁶³-1 ( ≈ 9×10¹⁵) | 64 bits / 8 bytes |
i128 | -2¹²⁷ ( ≈ -34×10³⁷) to 2¹²⁷-1 ( ≈ 34×10³⁷) | 128 bits / 16 bytes |
Floating-point numbers
| Type | Values | Size |
|---|---|---|
f32 | See description | 32 bits / 4 bytes |
f64 | See description | 64 bits / 8 bytes |
Floating-point numbers are defined in IEEE 754-2008. They can mostly be considered as decimal numbers, for a deeper explanation, please refers to the Single-precision floating-point format (for f32) and Double-precision floating-point format (for f64) articles on Wikipedia.
They can store positive or negative values, but also be in one of those three states:
- positive infinity, can be result of something like
1.0/0.0; - negative infinity, can be result of something like
-1.0/0.0; - not a number, can be result of a square root of negative number (aka. complex number).
Textual data
| Type | Values | Size |
|---|---|---|
char | Any valid Unicode scalar value | 32 bits / 4 bytes |
string | Any valid UTF-8 text | Variable |
All textual information is represented as Unicode. A char uses 4 bytes to store any Unicode scalar value, as defined in Unicode Standard. Unlike many other programming languages, Mélodium does not assume a char and a byte (nor combination of bytes) to be equivalent at all, for many reasons such as:
- a byte only have 256 values, while all human languages combined have much more “letters”;
- a letter in Unicode Text Format can be up to 4 bytes;
- many values are illegal according to Unicode;
- Unicode standard provide a strong universality of what textual data can be represented;
- making data types reliable, each one having its own purpose, then
charguarantees valid text data whilebyteonly assume it is data.
The string data type can represent any UTF-8 text and its size depends on the length of the text. Interestingly, strings are not a combination of chars, but real UTF-8 strings. Taking the text Mélodium and putting it as vector of chars, 32 bytes (8 chars × 4 bytes) are used, but as string only 9 bytes. This technical subtility is transparent for users and conversion treatments are provided if needed.
Mélodium can handle many encodings through its encoders and decoders, taking and providing byte streams.
Parameters
Treatments and models declares parameters. Parameters are like in any language: elements given by the caller to set up behavior of the model or treatment.
Const and var
In Mélodium, parameters can be either constant or variable, respectively declared with keywords const and var.
A constant parameter designates something that will keep the same value during all the execution, on all tracks generated through the given call. They are used mostly to configure models, that have all parameters required to be constant.
A variable parameter designates something that may have different values on each track generated.
While a constant can be used to set up constant and variable parameters, variable elements (parameters but also contexts) can only be used to set up other variables.
Configuration parameters
Treatments and models can also declare configuration parameters, written in square brackets ([param: Type]). These are used to pass models (or other fixed resources) into a treatment, and are always constant. They are set once when the treatment is wired up and do not change at runtime.
// database is a configuration parameter: it receives a model instance.
treatment userData[database: SqlPool]()
input user_id: Block<string>
output result: Block<Option<string>>
{
// database is available here as a fixed resource.
}
Model parameters are by definition always const, since a model lives for the full duration of the program and its configuration cannot change between tracks.
Generics
Generics are a mechanism allowing to rely on type abstraction to process data.
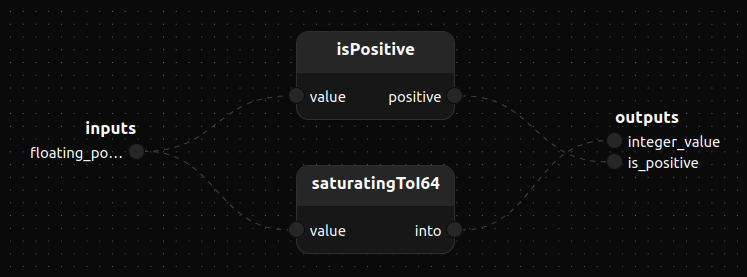
use std/ops/num::isPositive
use std/conv::saturatingToI64
treatment demonstration()
input floating_point_value: Stream<f32>
output integer_value: Stream<i64>
output is_positive: Stream<bool>
{
// Treatments isPositive and saturatingToI64 are depending on generic type,
// that have to be given at instanciation.
isPositive<f32>()
saturatingToI64<f32>()
Self.floating_point_value ------> isPositive.value,positive --> Self.is_positive
Self.floating_point_value -> saturatingToI64.value,into ------> Self.integer_value
}
Reference for isPositive, saturatingToI64
Traits restriction
Instead of allowing any kind of data, generics can be restrained to specific traits, requiring the given data type to implement these traits to be used with the element.
use std/ops/num::isPositive
use std/conv::saturatingToI64
// A treatment can have generic parameter, with optionnal trait restrictions,
// in order to fit its functionnal abilities.
treatment demonstration<N: Float + SaturatingToI64>()
// Generics can be used at any place a type can be given.
input floating_point_value: Stream<N>
output integer_value: Stream<i64>
output is_positive: Stream<bool>
{
// As N fits the Float and SaturatingToI64 traits,
// it can be passed to those treatments too.
isPositive<N>()
saturatingToI64<N>()
Self.floating_point_value ------> isPositive.value,positive --> Self.is_positive
Self.floating_point_value -> saturatingToI64.value,into ------> Self.integer_value
}
Traits
Traits are intrinsic abilities of a given type. They define what operations a type supports: whether it can be added, compared, converted, serialized, displayed, and so on.
Any type can implement any trait, as long as it has a logical meaning for that type. For example, u32 implements Add (addition makes sense for integers), but bool does not implement Div (dividing booleans has no meaning).
Why traits matter
Traits are most useful in two situations:
Constraining generics. When writing a generic treatment that works on any numeric type, traits let you express that constraint precisely. A generic <N: Add + PartialOrder> accepts any type that supports addition and comparison, and nothing else.
// Only types that implement SaturatingToI64 and Float can be used here.
treatment demonstration<N: Float + SaturatingToI64>()
input value: Stream<N>
output integer: Stream<i64>
{
saturatingToI64<N>()
Self.value -> saturatingToI64.value,into -> Self.integer
}
Understanding what a type can do. When using a type from a package, its documentation lists its implemented traits. If a type implements Serialize, you can pass it to treatments that serialize data. If it implements Equality, you can compare two instances.
Trait families
Traits are organized in families by purpose:
- Conversions (
ToI8,ToF64,ToString, …): infallible type conversions. - Fallible conversions (
TryToI8,TryToU32, …): conversions that may fail, returningOption<T>. - Arithmetic (
Add,Sub,Mul,Div,Neg,Pow, …): mathematical operations. - Checked arithmetic (
CheckedAdd,CheckedSub, …): arithmetic that returnsOption<T>on overflow. - Saturating arithmetic (
SaturatingAdd,SaturatingMul, …): arithmetic that clamps at the type boundary. - Comparison (
PartialEquality,Equality,PartialOrder,Order): equality and ordering. - Numeric (
Signed,Float,Bounded): numeric classification traits. - Serialization (
Serialize,Deserialize): data encoding and decoding. - Display (
ToString): human-readable representation.
The complete list of traits and their implementation per core type is available in the Trait list. In practice, the documentation page for each type is the most direct way to see which traits it implements.
Traits list
Here is the exhaustive list of Mélodium traits.
Some traits are grouped by family, as they behave the same way. The behavior is then explained with general meaning, and each individual trait description exposes some specificities.
Infaillible conversions
Infaillible conversions designates conversions that are guaranteed to succeed, for which for every X initial state there exist a Y result state.
While these conversions are guaranteed to succeed, they are not guaranteed to be reversible. As example,
u8implementsToI64, buti64does not implementsToU8.
These traits are mostly useful trough treatments and functions of the conv area.
ToI8
Type is able to convert itself into a i8 value.
| Implemented by |
|---|
i8 |
ToI16
Type is able to convert itself into a i16 value.
| Implemented by |
|---|
i8 |
u8 |
ToI32
Type is able to convert itself into a i32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
u8 |
u16 |
ToI64
Type is able to convert itself into a i64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
u8 |
u16 |
u32 |
ToI128
Type is able to convert itself into a i128 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
ToU8
Type is able to convert itself into a u8 value.
| Implemented by |
|---|
u8 |
byte |
ToU16
Type is able to convert itself into a u16 value.
| Implemented by |
|---|
u8 |
u16 |
ToU32
Type is able to convert itself into a u32 value.
| Implemented by |
|---|
u8 |
u16 |
u32 |
ToU64
Type is able to convert itself into a u64 value.
| Implemented by |
|---|
u8 |
u16 |
u32 |
u64 |
ToU128
Type is able to convert itself into a u128 value.
| Implemented by |
|---|
u8 |
u16 |
u32 |
u64 |
u128 |
ToF32
Type is able to convert itself into a f32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
ToF64
Type is able to convert itself into a f64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
ToBool
Type is able to convert itself into a bool value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
bool |
byte |
ToByte
Type is able to convert itself into a byte value.
| Implemented by |
|---|
u8 |
bool |
byte |
ToChar
Type is able to convert itself into a char value.
| Implemented by |
|---|
char |
ToString
Type is able to convert itself into a string value.
While it is useful to have a conversion to
stringfor a type, it should not be considered as a “readable” version of the value, and so not be confused withDisplaytrait, that is especially designed for this purpose.
| Implemented by |
|---|
void |
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Faillible conversions
Faillible conversions designates conversions that are possible without being guaranteed to succeed.
Those conversions are useful to get an Option<T> result, where T is the target type, containing a value if conversion succeed, or none if it cannot be done.
These traits are mostly useful trough treatments and functions of the conv area.
A general rule is that when a type implements a
To*trait, it also does for itsTryTo*counterpart.
TryToI8
Type can try to convert itself into a i8 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToI16
Type can try to convert itself into a i16 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToI32
Type can try to convert itself into a i32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToI64
Type can try to convert itself into a i64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToI128
Type can try to convert itself into a i128 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToU8
Type can try to convert itself into a u8 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToU16
Type can try to convert itself into a u16 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToU32
Type can try to convert itself into a u32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToU64
Type can try to convert itself into a u64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToU128
Type can try to convert itself into a u128 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToF32
Type can try to convert itself into a f32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToF64
Type can try to convert itself into a f64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
TryToBool
Type can try to convert itself into a bool value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
bool |
byte |
TryToByte
Type can try to convert itself into a byte value.
| Implemented by |
|---|
u8 |
bool |
byte |
TryToChar
Type can try to convert itself into a char value.
| Implemented by |
|---|
char |
TryToString
Type can try to convert itself into a string value.
| Implemented by |
|---|
void |
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Saturating conversions
Saturating conversions are specific kind of conversions where a type can try to convert itself into another one, and instead of failing the conversion if its value cannot be rendered into the target type, push to the closest bound of that type according to initial value.
This kind of trait exists to target numeric types.
SaturatingToI8
Type can make a saturating conversion to i8 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToI16
Type can make a saturating conversion to i16 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToI32
Type can make a saturating conversion to i32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToI64
Type can make a saturating conversion to i64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToI128
Type can make a saturating conversion to i128 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToU8
Type can make a saturating conversion to u8 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToU16
Type can make a saturating conversion to u16 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToU32
Type can make a saturating conversion to u32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToU64
Type can make a saturating conversion to u64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToU128
Type can make a saturating conversion to u128 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToF32
Type can make a saturating conversion to f32 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
SaturatingToF64
Type can make a saturating conversion to f64 value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Bounded
The type have minimum and maximum limits.
This trait is mostly useful trough functions of the types area.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
byte |
Binary
Type can be used for meaningful mathematical binary operations.
This trait is mostly useful trough treatments and functions of the bin area.
| Implemented by |
|---|
bool |
byte |
Signed
Type is signed, meaning it can have negative values.
This trait is mostly useful trough treatments and functions of the num area.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
f32 |
f64 |
Float
Type represent floating-point values, and is able to proceed to floating-point arithmetic.
This trait is mostly useful trough treatments and functions of the float area.
| Implemented by |
|---|
f32 |
f64 |
PartialEquality
Type can be compared to itself and tell wether both values are equal or not.
PartialEquality does not require a full equivalence between all the value of a type.
As example, for f32 and f64, NaN is not equal to itself. As such, those types implements PartialEquality but not Equality.
This trait is mostly useful trough treatments and functions of the ops area.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Equality
Type can be compared to itself and tell wether both values are equal or not.
Equality require a full equivalence between all the value of a type, meaning any X value is always equal to itself and always different from any other.
This trait is mostly useful trough treatments and functions of the ops area.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
bool |
byte |
char |
string |
PartialOrder
Type implements partial order, meaning values of this type can be compared in a way telling if one is greater or lesser to another, strictly or not.
This trait is mostly useful trough treatments and functions of the ops area.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Order
Type implements total order, meaning values of this type can be compared, and absolute minimums and maximums in a set of those values can be found.
This trait is mostly useful trough treatments and functions of the ops area.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Basic arithmetic
Those traits corresponds to basic arithmetic operations, that are guaranteed to give a result, while that one may not be meaningful in some cases.
Those operations can most notably be subject to overflow, meaning the result value of an operation cannot fit into the type on which it is applied.
This trait is mostly useful trough treatments and functions of the num area.
Add
Type can proceed to addition between two values.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Sub
Type can proceed to substraction of two values.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Mul
Type can proceed to multiplication of two values.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Div
Type can proceed to division of a value by another.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Rem
Type can proceed to division of a value by another and give the remainder.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Neg
Type can negates its values.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
f32 |
f64 |
Pow
Type can elevates its values by an exponent.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
Euclid
Type can proceed to euclidian division of a value by another.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
Checked arithmetic
Those traits corresponds to basic arithmetic operations, that may have meaningless result.
Those operations can avoid overflows, as the result value of an operation that cannot fit into the type is ignored.
This trait is mostly useful trough treatments and functions of the num area.
CheckedAdd
Type can proceed to addition between two values and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
CheckedSub
Type can proceed to substraction of two values and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
CheckedMul
Type can proceed to multiplication of two values and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
CheckedDiv
Type can proceed to division of a value by another and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
CheckedRem
Type can proceed to division of a value by another and give the remainder, while avoiding meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
CheckedNeg
Type can negates its values and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
CheckedPow
Type can elevates its values by an exponent and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
CheckedEuclid
Type can proceed to euclidian division of a value by another and avoid meaningless results.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
Saturating arithmetic
Those traits corresponds to basic arithmetic operations, that saturates the value to the closest bound to truth if the result cannot fit into the type.
This trait is mostly useful trough treatments and functions of the num area.
SaturatingAdd
Type can proceed to addition between two values, and bound to minimum or maximum value if addition result is out of range.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
SaturatingSub
Type can proceed to substraction of two values, and bound to minimum or maximum value if substraction result is out of range.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
SaturatingMul
Type can proceed to multiplication of two values, and bound to minimum or maximum value if multiplication result is out of range.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
Wrapping arithmetic
Those traits corresponds to basic arithmetic operations, that wraps on purpose when the operation result goes out of range for the subject type.
This trait is mostly useful trough treatments and functions of the num area.
WrappingAdd
Type can proceed to addition between two values, and wrap over its value range if addition exceeds type boundaries.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
WrappingSub
Type can proceed to substraction of two values, and wrap over its value range if substraction exceeds type boundaries.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
WrappingMul
Type can proceed to multiplication of two values, and wrap over its value range if multiplication exceeds type boundaries.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
WrappingNeg
Type can negates its values, and wrap over its value range if negation exceeds type boundaries.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
Hash
Type is subject to hash, and so can be used as key to reference data.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
bool |
byte |
char |
string |
Serialize
Type implements serialization, meaning it can be turned into linear data and send out from a program.
| Implemented by |
|---|
void |
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Deserialize
Type implements deserialization, meaning it can be received from outside of a program and parsed to build a value.
| Implemented by |
|---|
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Display
Type can be rendered as human readable string and possibly displayed to users in a way making sense for them.
Displaytrait is different to theToStringtrait as it does not have the same functionnal purpose.ToStringis expected to be a technical conversion of data, whileDisplayis meant to expose it to human eyes.
| Implemented by |
|---|
void |
i8 |
i16 |
i32 |
i64 |
i128 |
u8 |
u16 |
u32 |
u64 |
u128 |
f32 |
f64 |
bool |
byte |
char |
string |
Script files
Launch
Mélodium scripts can be launched using melodium command:
melodium main_script.mel
Or if the main script includes a shebang:
./main_script.mel
Recommended shebang being #!/usr/bin/env melodium.
Script file must contains basic identity informations to be used as entrypoint:
- name (required),
- version (optional, in semver sematic),
- requirements (optional).
#!/usr/bin/env melodium
#! name = my_script
#! version = 0.1.0
#! require = std:0.8.0 fs:0.8.0 …
// Content
Note about encoding
Mélodium script files are plain UTF-8 text, without byte order mark. This choice is made for three main reasons:
- a choice on encoding, even arbitrary, is better than no choice;
- Unicode provides the wider support for any characters from all human languages and scripts, existing and future, ensuring continuity;
- the Mélodium engine is implemented in Rust, itself natively representing text as UTF-8.
Project Organization
Mélodium projects are organized through a root folder, containing a Compo.toml file, and .mel files.
my_project/
├── Compo.toml
├── baz.mel
├── foo
│ └── bar.mel
├── foo.mel
└── main.mel
Areas
In Mélodium, an area is an element location. It is a concept similar to Rust modules or Java locations.
An area is materialized by a .mel file, that contains all its elements.
Subareas are made using a folder having the area name, and creating .mel files inside.
my_project/
├── Compo.toml
├── baz.mel
├── foo # folder for subareas
│ └── bar.mel
├── foo.mel # area
└── main.mel
In this example, the foo area is developed within the foo.mel file, and bar area is located within the foo/ folder to be a subarea of foo.
They can respectively be called through:
root/foo::<element>root/foo/bar::<element>
Current project references
In Mélodium, project code can refer to its own content using the root and local keywords, and do not use the name of the project itself.
In the example, to refer an element that is present in the baz area, the call root/baz::<element> must be used.
Similarly, if foo area refers to something within bar, local/bar::<element> could be written.
Compo.toml
Compo.toml file is the very file making a folder being a Mélodium project.
Its structure is really basic, containing few informations about the project:
name = "my_project"
version = "0.0.1"
[dependencies]
encoding = "0.8.0"
fs = "0.8.0"
http = "0.8.0"
javascript = "0.8.0"
[entrypoints]
main = "my_project/main::main"
Name and version
The name field contains the very name of the project, that will be exposed in repository and used by dependents projects to call it.
Dependencies
The dependencies list contains the names of dependencies and version requirements, as explained in the dedicated chapter.
Entrypoints
The entrypoints list contains the named entrypoints and targeted treatments.
Dependencies
Mélodium is not only a language and execution engine, but a dependency manager too.
Mélodium, as dependency manager, is largely inspired from Rust Cargo. If you’re already familiar with the way
cargowork with dependencies, you shouldn’t discover new things here.
The dependency and package management in Mélodium is still at its early stage, and things may change about it in the future. Information presented here is about actual state and not written in stone.
Dependency list
Every Mélodium project have a dependency list, that it requires to work.
This list is made in the Compo.toml file.
A usual dependency list can be:
std>=0.8.0http>=0.8.0fs>=0.8.0
Note that the std dependency in Mélodium have to be explicitly given.
This is mainly because standard library is in quick evolution and require to rely on precise version.
Dependency tree
Each project having its own dependency list, using a project means building a dependency tree. Mélodium is quite cool about dependencies management, but have some rules:
- a project cannot rely directly on other versions of that same project (but multiple versions can appear in the dependency tree);
- circular dependencies are forbidden, meaning a project of a given version cannot appear anywhere in its own dependency tree.
Semantic Versionning
Mélodium follows the semantic versioning norm SemVer. This versioning system aims to be consistent with software evolution and avoid custom version designation caveats.
A version is always designated as x.y.z, with optionnal pre-release identifier added at the end as x.y.z-rc1.
This page is essentially an adaptation from the Cargo Rust manual to Mélodium, from which the versioning and dependency system is largely inspired.
Version designation
[dependencies]
regex = "0.8.1"
The string "0.8.1" is a version requirement. Although it looks like a
specific version of the regex package, it actually specifies a range of
versions and allows SemVer compatible updates. An update is allowed if the new
version number does not modify the left-most non-zero number in the major, minor,
patch grouping. In this case, we may have version 0.8.3 if it is the latest 0.8.z release, but would not
update us to 0.9.0. If instead we had specified the version string as 1.0,
cargo should update to 1.1 if it is the latest 1.y release, but not 2.0.
The version 0.0.x is not considered compatible with any other version.
Here are some more examples of version requirements and the versions that would be allowed with them:
1.2.3 := >=1.2.3, <2.0.0
1.2 := >=1.2.0, <2.0.0
1 := >=1.0.0, <2.0.0
0.2.3 := >=0.2.3, <0.3.0
0.2 := >=0.2.0, <0.3.0
0.0.3 := >=0.0.3, <0.0.4
0.0 := >=0.0.0, <0.1.0
0 := >=0.0.0, <1.0.0
This compatibility convention is different from SemVer in the way it treats
versions before 1.0.0. While SemVer says there is no compatibility before
1.0.0, Mélodium considers 0.x.y to be compatible with 0.x.z, where y ≥ z
and x > 0.
It is possible to further tweak the logic for selecting compatible versions using special operators as described in the next section.
Use the default version requirement strategy, e.g. std = "1.2.3" where possible to maximize compatibility.
Version requirement syntax
Caret requirements
Caret requirements are the default version requirement strategy.
This version strategy allows SemVer compatible updates.
They are specified as version requirements with a leading caret (^).
^1.2.3 is an example of a caret requirement.
Leaving off the caret is a simplified equivalent syntax to using caret requirements. While caret requirements are the default, it is recommended to use the simplified syntax when possible.
log = "^1.2.3" is exactly equivalent to log = "1.2.3".
Tilde requirements
Tilde requirements specify a minimal version with some ability to update. If you specify a major, minor, and patch version or only a major and minor version, only patch-level changes are allowed. If you only specify a major version, then minor- and patch-level changes are allowed.
~1.2.3 is an example of a tilde requirement.
~1.2.3 := >=1.2.3, <1.3.0
~1.2 := >=1.2.0, <1.3.0
~1 := >=1.0.0, <2.0.0
Wildcard requirements
Wildcard requirements allow for any version where the wildcard is positioned.
*, 1.* and 1.2.* are examples of wildcard requirements.
1.* := >=1.0.0, <2.0.0
1.2.* := >=1.2.0, <1.3.0
Note: Mélodium does not allow bare
*versions.
Comparison requirements
Comparison requirements allow manually specifying a version range or an exact version to depend on.
Here are some examples of comparison requirements:
>= 1.2.0
> 1
< 2
= 1.2.3
Multiple version requirements
As shown in the examples above, multiple version requirements can be
separated with a comma, e.g., >= 1.2, < 1.5.
Entrypoints
Mélodium projects can have entrypoints. As their name suggest, they are the treatments that can be called directly to start a Mélodium program.
A project is not required to have entrypoints, if it is a library as example. On the opposite, a project can have multiple entrypoints, if that project is a program that can be used in different situations.
Naming entrypoints
Entrypoints are essentially a name associated with a treatment path, like:
server:my_project/foo::serveclient:my_project/bar::requestmain:my_project/etc::main
Entrypoints names have same restriction as treatments names but don’t have to be the same as the treatment they designates.
The entrypoint name is expected to be typed in command line, as commands of the program:
// Starts 'my_program' with 'server' entrypoint
$ my_program.jeu server
// With explicit melodium command
$ melodium my_program.jeu server
An exception is made for the main entrypoint, that if present, is called directly if no specific entrypoint is given to program.
// Starts 'my_program' with 'main' entrypoint
$ my_program.jeu
// With explicit melodium command
$ melodium my_program.jeu
Entrypoints parameters
If a treatment used as entrypoint have parameters, they automatically becomes acceptable command arguments.
// In root/foo
treatment serve(bind: string = "localhost", port: u16)
{
/*
Implementation…
*/
}
With entrypoint server: my_project/foo::serve.
$ my_program.jeu server --port 6789 --bind 192.168.55.66
Standalone Files
Mélodium is able to handle standalone .mel files. Opposite to .jeu files that are packaged Mélodium applications, .mel standalone files aims to stay as simple scripts, for use cases as quick deployment, small tooling, or administration helpers.
Standalone Mélodium files are really usual .mel files with a special heading.
#!/usr/bin/env melodium
#! name = my_project_name
#! version = 0.1.0
#! require = std:0.8.*
/*
Just a usual Mélodium script afterwards.
…
*/
They always start with the #!/usr/bin/env melodium shebang, allowing them to be used as system script.
This shebang is mandatory as it is also used by Mélodium engine to ensure script was designed to be called as-is.
name and version fields works the same as in Compo.toml. require is expected to be the list of dependencies, separated by spaces, in with the <name>:<version_requirement> format.
require can also be repeated multiple times if needed.
Unlike other Mélodium projects, standalone Mélodium files are required to have one and only one entrypoint, that is always set up to the main treatment. All the characteristics relevant to treatement parameters and CLI arguments are applicable as for any entrypoint.
Error Handling
Mélodium has no exceptions. Errors are data, flowing through dedicated outputs just like any other value. A treatment that can fail exposes this through its output ports rather than interrupting execution.
The standard error pattern
Most treatments that interact with external systems (files, network, databases) expose a consistent set of outputs:
completed: Block<void>- emitted when the operation finishes successfully.failed: Block<void>- emitted when the operation fails.finished: Block<void>- emitted when the operation ends, regardless of whether it succeeded or failed.errors: Stream<string>- streams error messages as they occur.
use fs/local::writeTextLocal
use std/engine/log::logErrors
use std/engine/log::logInfoMessage
treatment saveResult(path: string)
input text: Stream<string>
{
writeTextLocal(path=path)
logErrors(label="save")
logSuccess: logInfoMessage(label="save", message="file written successfully")
Self.text -----------------------> writeTextLocal.text
writeTextLocal.errors ---------> logErrors.data
writeTextLocal.completed ------> logSuccess.trigger
}
Reference for writeTextLocal, logErrors, logInfoMessage
Unused outputs are legal: if failed and errors are not connected, error information is silently dropped. This is valid but not recommended for production code.
Handling failure explicitly
When the distinction between success and failure matters for the program flow, connect failed to a handler treatment. The failed output fires a Block<void> trigger, which can chain into other treatments:
use fs/local::readTextLocal
use std/flow::emit
use std/engine/log::logErrorMessage
use std/engine/log::logErrors
treatment loadConfig(path: string)
input trigger: Block<void>
output text: Stream<string>
{
readTextLocal(path=path)
logErrors(label="config")
logFail: logErrorMessage(label="config", message="could not read config file")
Self.trigger -----------------> readTextLocal.trigger
readTextLocal.text -----------> Self.text
readTextLocal.errors ---------> logErrors.data
readTextLocal.failed ---------> logFail.trigger
}
Option for absence
Functions and some treatments return Option<T> when a value may or may not be present, rather than using a separate error output. Option<T> is either Some(value) or None.
The std package provides treatments for working with options: unwrapOr substitutes a default when the value is None, and check/uncheck split a stream into present and absent paths.
use std/ops/option::unwrapOr
treatment withDefault()
input value: Stream<Option<string>>
output result: Stream<string>
{
unwrapOr<string>(default="(none)")
Self.value -> unwrapOr.option,value -> Self.result
}
Reference for unwrapOr
Summary
| Situation | Mechanism |
|---|---|
| Operation may fail | failed: Block<void> output |
| Error messages | errors: Stream<string> output |
| Successful completion | completed: Block<void> output |
| Value may be absent | Option<T> return type |
Because errors are just data, the same connection rules apply: they can be logged, counted, transformed, or forwarded to other treatments exactly like any other stream.
Walkthrough
This page builds a complete program from scratch, introducing each concept as it is needed. The program reads a text file, trims whitespace from each line, and writes the result to another file.
It uses only the std and fs packages and is fully runnable.
Step 1: the project files
Create this structure:
trimmer/
├── Compo.toml
└── main.mel
Compo.toml:
name = "trimmer"
version = "0.1.0"
[dependencies]
std = "0.10.1"
fs = "0.10.1"
[entrypoints]
main = "trimmer/main::main"
The main entrypoint points to the main treatment in main.mel.
Step 2: the entry point
Start with a treatment that accepts two file paths as parameters:
use std/engine/util::startup
treatment main(const input: string = "input.txt", const output: string = "output.txt")
{
startup()
// More to come here.
startup.trigger -> /* ... */
}
startup() is a treatment backed by the built-in Engine model. It fires a Block<void> trigger when the program is ready to run. Because input and output are const parameters, they are fixed for the entire execution and can be passed on the command line:
melodium run Compo.toml --input data.txt --output result.txt
Step 3: reading the file
Add readTextLocal, which reads a file from the local filesystem and streams its content as a Stream<string>:
use std/engine/util::startup
use fs/local::readTextLocal
treatment main(const input: string = "input.txt", const output: string = "output.txt")
{
startup()
readTextLocal(path=input)
startup.trigger -> readTextLocal.trigger
}
readTextLocal waits for a Block<void> trigger before opening the file, then streams text through its text output. It also exposes completed, failed, and errors outputs for error handling.
Step 4: transforming each line
Add trim to strip leading and trailing whitespace from each string in the stream:
use std/engine/util::startup
use std/text/compose::trim
use fs/local::readTextLocal
treatment main(const input: string = "input.txt", const output: string = "output.txt")
{
startup()
readTextLocal(path=input)
trim()
startup.trigger -> readTextLocal.trigger
readTextLocal.text -> trim.text
}
trim receives a Stream<string> and outputs Stream<string> (as trimmed). Every line coming out of readTextLocal flows through trim before going anywhere else.
Step 5: writing the result
Add writeTextLocal to write the processed stream to the output file:
use std/engine/util::startup
use std/text/compose::trim
use fs/local::readTextLocal
use fs/local::writeTextLocal
treatment main(const input: string = "input.txt", const output: string = "output.txt")
{
startup()
readTextLocal(path=input)
trim()
writeTextLocal(path=output)
startup.trigger -> readTextLocal.trigger
readTextLocal.text -> trim.text,trimmed -> writeTextLocal.text
}
The , shorthand on trim.text,trimmed chains the text input and trimmed output of the same treatment instance, keeping the connection line compact.
Step 6: handling errors
readTextLocal and writeTextLocal both expose errors: Stream<string> and failed: Block<void>. Connect them to the log so failures are visible:
use std/engine/util::startup
use std/text/compose::trim
use fs/local::readTextLocal
use fs/local::writeTextLocal
use std/engine/log::logErrors
use std/engine/log::logErrorMessage
treatment main(const input: string = "input.txt", const output: string = "output.txt")
{
startup()
readTextLocal(path=input)
trim()
writeTextLocal(path=output)
readErrors: logErrors(label="read")
writeErrors: logErrors(label="write")
readFail: logErrorMessage(label="read", message="failed to read input file")
writeFail: logErrorMessage(label="write", message="failed to write output file")
startup.trigger -> readTextLocal.trigger
readTextLocal.text -> trim.text,trimmed -> writeTextLocal.text
readTextLocal.errors -> readErrors.data
readTextLocal.failed -> readFail.trigger
writeTextLocal.errors -> writeErrors.data
writeTextLocal.failed -> writeFail.trigger
}
Nothing else changes: the main data path is unaffected. Error paths are simply additional branches from the same treatment instances.
The complete program
use std/engine/util::startup
use std/text/compose::trim
use fs/local::readTextLocal
use fs/local::writeTextLocal
use std/engine/log::logErrors
use std/engine/log::logErrorMessage
treatment main(const input: string = "input.txt", const output: string = "output.txt")
{
startup()
readTextLocal(path=input)
trim()
writeTextLocal(path=output)
readErrors: logErrors(label="read")
writeErrors: logErrors(label="write")
readFail: logErrorMessage(label="read", message="failed to read input file")
writeFail: logErrorMessage(label="write", message="failed to write output file")
startup.trigger -> readTextLocal.trigger
readTextLocal.text -> trim.text,trimmed -> writeTextLocal.text
readTextLocal.errors -> readErrors.data
readTextLocal.failed -> readFail.trigger
writeTextLocal.errors -> writeErrors.data
writeTextLocal.failed -> writeFail.trigger
}
Reference for startup, readTextLocal, trim, writeTextLocal
Running it
melodium run Compo.toml
With custom paths:
melodium run Compo.toml --input data.txt --output result.txt
What this demonstrates
constparameters become CLI arguments automatically.startup()is how a program begins: every graph needs an event source.- Treatment instances can be labeled (
readErrors:,writeFail:) to distinguish multiple uses of the same treatment. - Error outputs are just additional connection points, not a separate mechanism.
- Declaration order does not matter:
startupis declared first, but the connections define the actual execution order.
Reference
The Mélodium reference is available on doc.melodium.tech. The whole Standard Library is documented there, and can be browsed through areas.
Release
Releasing a Mélodium project as application aims to be extremely simple.
It mostly consists in packaging it as Jeu file and distribute it.
Package
To build a packaged Mélodium application, run the melodium jeu build command:
$ melodium jeu build <PROJECT_LOCATION> <OUTPUT_FILE>
This will check the given project and package it in a resulting .jeu file.
Run
To run a packaged Mélodium application, the host system must have Mélodium installed.
Considering the file is myapp.jeu, it can be run through direct call or with explicit melodium command:
// Direct call
$ ./myapp.jeu
// Explicit Mélodium call
$ melodium run myapp.jeu
Distribute
Jeu files can be distributed as-is. The host machine only need Mélodium to be installed.
Jeufiles are already highly compressed data (using the LZMA2 algorithm), storing and distributing them in re-compressed files is not useful.
Containers
Mélodium applications can be easily containerized by putting them in a container image alongside a Mélodium installation.
This chapter is being built alongside the Mélodium container images design.
Information to come soon.
Glossary
Area
A namespace unit in Mélodium, materialized by a .mel file. Subareas are created by placing .mel files inside a folder with the parent area’s name. Elements within the same project are referenced using root/area::element or local/subarea::element.
See: Project Organization
Block
A port kind written Block<T> that carries exactly one value of type T. Used for single events, triggers, and configuration values. The name refers to a single block of data, not to suspending execution.
See: Connections
Configuration parameter
A parameter written in square brackets ([param: Type]) on a treatment declaration, used to pass a model instance or fixed resource into a treatment. Configuration parameters are always constant.
See: Parameters
Connection
A directed link from an output port to an input port, written with ->. Connections define the data flow between treatment instances inside a treatment body. A connection must link ports of the same type and kind, cannot create cycles, and a given input may only have one connection.
See: Connections
Context
Track-wide data prefixed with @, provided by a source treatment and implicitly available to any treatment in the same track that declares require @ContextName. Unlike parameters, contexts do not need to be explicitly passed down the call chain.
See: Contexts
Entrypoint
A named treatment that can be invoked directly from the command line to start a program. Declared in Compo.toml. The main entrypoint is called when no name is given. Treatment parameters become CLI arguments automatically.
See: Entrypoints
Function
A pure, side-effect-free callable prefixed with |, used to compute parameter values. Functions are executed once at program initialization when used as const parameters, or once per track creation when used as var parameters.
See: Functions
Model A stateful element that lives for the entire program execution. Models are the sources of events and tracks: they are the starting points from which data enters the system. A model is declared by extending a library model and configuring its parameters. See: Models
Self
A keyword used inside a treatment body to refer to the hosting treatment’s own input and output ports. Self.input_name and Self.output_name wire the treatment’s declared ports into its internal connection graph.
See: Treatments
Stream
A port kind written Stream<T> that carries a continuous, unbounded sequence of values of type T. The general case for data transmission in Mélodium.
See: Connections
Track The complete set of treatment instances and connections created together from a single model event. Each event from a model spawns a new independent track. All tracks run concurrently, each with its own data and context. See: Tracks
Trait
An intrinsic capability of a type, such as the ability to be added (Add), compared (PartialEquality), or converted to a string (ToString). Traits are used to constrain generic type parameters.
See: Traits
Treatment The primary computation unit in Mélodium. A treatment declares inputs, outputs, and a body of other treatment instances connected together. Treatments do not execute line by line; all inner treatments run concurrently when data is available. See: Treatments
void
A core type that carries no value. Block<void> is used as a trigger (signals that something happened), and Stream<void> is used as a continuation indicator (signals ongoing activity without conveying data).
See: Core types
About the author
Quentin Vignaud is IT engineer graduated from CESI, and M.Sc. in computing science from UQÀM. Working at Doctolib as data and software engineer, originally authored Mélodium during studies at UQÀM, while doing scientific research in music analysis.
Website: https://www.quentinvignaud.com/